Este artículo aborda el desarrollo de una herramienta de diagnóstico para el mantenimiento predictivo de sistemas de liofilización industriales. En el núcleo del sistema se encuentra un algoritmo de detección de anomalías diseñado para identificar patrones anómalos en los datos operativos. A través de su desarrollo, se han identificado estrategias de diagnóstico clave para mejorar la confiabilidad del sistema y la detección temprana de fallos, con el objetivo final de reducir el tiempo de inactividad y costos operativos.
En los últimos años, el mantenimiento predictivo ha ganado protagonismo como elemento clave en la transformación digital de las industrias, particularmente en la gestión de equipos industriales farmacéuticos, como los liofilizadores. Este planteamiento tiene como objetivo anticipar los fallos de los equipos, optimizar los procesos de mantenimiento y reducir tanto los costes como los tiempos de parada no planificados. Los avances en tecnologías digitales, como el aprendizaje automático y la inteligencia artificial, han allanado el camino al desarrollo de sistemas cada vez más sofisticados capaces de detectar anomalías y predecir problemas técnicos.
Este artículo se centra en el diseño y desarrollo de un algoritmo de detección de anomalías para una plataforma de mantenimiento predictivo adaptada a los procesos de liofilización. La plataforma está diseñada para manejar grandes volúmenes de datos operativos en tiempo real, identificando patrones anómalos que podrían indicar posibles fallos del sistema. Aunque el algoritmo aún está en desarrollo, los primeros resultados ponen de manifiesto su potencial para mejorar la fiabilidad y la eficiencia del proceso de liofilización.
Flujo de trabajo de datos
La plataforma de mantenimiento predictivo desarrollada para equipos farmacéuticos se compone de múltiples capas de software y herramientas analíticas que facilitan la recopilación, transmisión segura y procesamiento de datos en tiempo real. Estos componentes de gestión de datos son esenciales para el diseño y operación del algoritmo de detección de anomalías.
Recopilación de datos
La primera fase implicó la integración de sensores y otros dispositivos de recopilación de datos en los liofilizadores. En lugar de depender de sensores habilitados para IoT, los datos se extraen directamente de los controladores lógicos programables (PLC), que gestionan y supervisan el proceso de liofilización. Estos PLC recopilan información relevante como temperatura, presión, niveles de vacío y otros valores de proceso críticos para el proceso de liofilización.
Para garantizar la transmisión segura de estos datos desde los PLC a la base de datos centralizada, el sistema emplea un sistema de entrada de alta seguridad. Este sistema de entrada actúa como una barrera protectora, administrando el flujo de datos desde los PLC al entorno de almacenamiento de datos al tiempo que aplica estrictos protocolos de ciberseguridad. Esto garantiza que los datos permanezcan protegidos contra el acceso no autorizado o ciberataques, salvaguardando la integridad de las operaciones del sistema.
El uso de estos accesos protegidos resulta crucial para garantizar un entorno seguro y controlado de intercambio de datos, indispensable para industrias que requieren datos precisos y confiables en la toma de decisiones operativas. Además, estos sistemas de entrada admiten el cifrado y los canales de datos seguros, lo que mejora aún más la capacidad de la plataforma para manejar información confidencial con los más altos niveles de seguridad.
Almacenamiento y gestión de datos
Una vez recopilados, los datos se transfieren a una base de datos centralizada que utiliza tecnologías de Big Data, diseñadas para gestionar de forma eficiente los grandes volúmenes de información generados por los liofilizadores. Este sistema centralizado permite la agregación fluida de datos, lo que garantiza que todas las métricas operativas se almacenen en una única ubicación accesible. La base de datos está diseñada teniendo en cuenta una alta disponibilidad, lo que minimiza el riesgo de pérdida de datos y garantiza un acceso continuo incluso durante el mantenimiento o interrupciones inesperadas.
Para proteger la integridad y la confidencialidad de los datos, toda la información se anonimiza antes del almacenamiento, eliminando cualquier identificador sensible y asegurando el cumplimiento de las normas de privacidad. Además, la infraestructura está equipada con múltiples capas de seguridad, incluidos el cifrado y los controles de acceso, para salvaguardar los datos contra el acceso no autorizado o brechas de seguridad.
Esta combinación de tecnologías de Big Data y sólidas medidas de seguridad garantiza que la plataforma pueda respaldar de forma eficaz el análisis de datos históricos y en tiempo real, manteniendo al mismo tiempo los más altos estándares de protección de datos.
Esta infraestructura de datos sirve como pilar central para el algoritmo de detección de anomalías, proporcionando los datos sin procesar necesarios para el análisis. A medida que el algoritmo evoluciona, este sistema centralizado admitirá modelos de aprendizaje automático y procesos de detección de anomalías más avanzados, garantizando que la plataforma siga siendo adaptable y escalable.
Desarrollo de algoritmos
El sistema de detección de anomalías es el núcleo de la plataforma, que se está desarrollando en colaboración con Dribia, una empresa especializada en análisis de datos. Su experiencia ha sido fundamental para sentar las bases del sistema y proponer el algoritmo de detección de anomalías apropiado que potencia la capacidad de la plataforma para detectar problemas operativos en los liofilizadores. Aunque el algoritmo todavía está en desarrollo y ensayo, éste está desarrollado mediante técnicas de aprendizaje automático no supervisado diseñadas para identificar patrones atípicos en datos operativos.
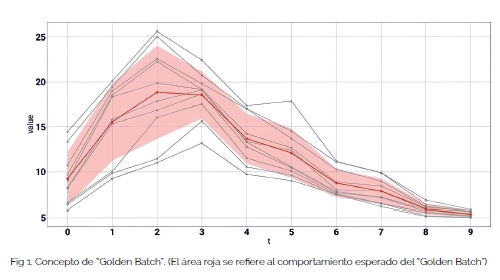
Una de las innovaciones clave introducidas a través de esta colaboración es el cálculo de un "Golden Batch" o “lote modelo”. Este concepto teórico sirve como base para definir el comportamiento operativo normal mediante la agregación de datos de múltiples ciclos de liofilización. El “Golden Batch” establece un punto de referencia claro, fijando un estándar de cómo debería comportarse el proceso en condiciones óptimas, como se ve en la Figura 1. Al promediar los datos de varias ejecuciones de producción, el sistema crea esta referencia de "Golden Batch", que luego se utiliza para comparar nuevos datos en tiempo real. Cualquier desviación de este estándar puede indicar posibles anomalías, lo que ayuda a los operadores a detectar problemas emergentes antes de que se agraven. Este enfoque es fundamental para comprender los parámetros operativos normales y sentar las bases para detectar desviaciones que puedan indicar posibles fallas.
Sin embargo, lograr un “Golden Batch” bien definido presenta desafíos significativos debido a la variabilidad natural inherente al proceso de liofilización. Factores como las condiciones ambientales, las características de la máquina y los ajustes del proceso introducen fluctuaciones que dificultan la creación de una línea base de aplicación universal, como se puede ver en la Figura 2. Esta variabilidad complica la generalización del algoritmo en diferentes máquinas y recetas, ya que los datos tienden a dispersarse alrededor de la media. Como resultado, si bien el concepto de “Golden Batch” ofrece una base teórica sólida, su implementación práctica requiere una optimización continua para tener en cuenta la amplia gama de condiciones operativas observadas en entornos del mundo real.
.jpg)
Para abordar estas complejidades, el algoritmo actual incorpora un mecanismo automático basado en un índice de anomalías. Este índice. Que cuantifica el grado de desviación respecto el lote de referencia, señala los problemas potenciales en tiempo real, como se muestra en el ejemplo de la figura 3. En los casos en los que el algoritmo captura las anomalías con precisión, este sistema de puntuación sirve como una herramienta eficaz para la predicción temprana de fallos.

Por ejemplo, al completar un ciclo de la máquina, como una prueba de fugas, el sistema calcula un índice de anomalía global. Este índice proporciona una evaluación general del comportamiento del sistema, lo que permite a los operadores evaluar rápidamente el rendimiento de la máquina. Sin embargo, este índice global se puede descomponer en grupos de variables específicas, principalmente Temperatura, Vacío y un tercer grupo, denominado X, como se puede ver en la Figura 4, que incluye variables relevantes adicionales.
Cada grupo está compuesto por varias variables relacionadas, y el algoritmo de detección de anomalías asigna puntuaciones de anomalía individuales a cada una de estas variables. La agregación de estas puntuaciones contribuye a la puntuación de anomalía general del grupo. Al analizar estas puntuaciones a nivel de grupo, los operadores pueden obtener información más detallada sobre qué parámetros específicos contribuyen más a la anomalía detectada. Este método no solo ayuda a identificar la fuente de problemas potenciales, sino que también destaca la importancia de cada variable dentro de su grupo, lo que permite un enfoque más específico para resolver desviaciones y optimizar el rendimiento.

Sin embargo, el desarrollo continuo del algoritmo se centra en mejorar su capacidad para distinguir entre variaciones operativas normales y anomalías reales, especialmente cuando se producen desviaciones sutiles o complejas debido a la variabilidad entre máquinas.
A pesar de estos desafíos, el concepto de “Golden Batch” sigue siendo una herramienta valiosa para establecer líneas de base claras, y el índice de anomalías ha demostrado ser eficaz para detectar ciertos patrones de falla. Cuando el sistema automatizado puede pasar por alto anomalías debido a la dispersión de datos, las metodologías tradicionales basadas en la dispersión aún desempeñan un papel importante. Estos métodos proporcionan una capa secundaria de detección de anomalías, comparando los puntos de datos actuales con la media y el rango de variación esperados. Esta combinación de enfoques automatizados y manuales garantiza que el sistema siga siendo adaptable y eficaz, incluso frente a entornos operativos complejos.
Validación y pruebas
El algoritmo de detección de anomalías se encuentra actualmente en un proceso exhaustivo de validación y pruebas en diferentes liofilizadores. Esta fase es fundamental para perfeccionar el sistema y adaptarlo a las complejidades operativas que introduce la variación de los datos. Los siguientes pasos en el proceso de desarrollo son los siguientes:
• Definir anomalías: establecer definiciones claras de lo que constituye una anomalía para el sistema, determinando valores umbral precisos para la puntuación de anomalía específica para cada grupo de datos, máquina y ciclo de proceso.
• Distinguir entre el funcionamiento nominal y las anomalías: mejorar la capacidad del algoritmo para distinguir entre el comportamiento operativo normal y las anomalías, dadas las fluctuaciones inherentes en los datos.
• Correlación entre sensores: Mejorar la correlación entre diferentes sensores y grupos de sensores para mejorar la precisión de la detección de anomalías y garantizar un control más integral del sistema.
• Aplicación en todas las máquinas: asegurar que el algoritmo se pueda generalizar y aplicar de manera efectiva a diferentes liofilizadores, teniendo en cuenta las variaciones en su comportamiento.
• Umbral adaptativo: implementar mecanismos de umbral adaptativo que puedan ajustarse automáticamente en función de las condiciones operativas cambiantes o las diferentes configuraciones de la máquina.
• Despliegue: planificar el despliegue del sistema de detección de anomalías, considerando las adaptaciones necesarias y los protocolos de prueba para diferentes entornos.
• Pruebas: realizar pruebas exhaustivas en condiciones reales para ajustar la precisión y la solidez del sistema en la detección de anomalías en diversas condiciones operativas.
• Validación: completar el proceso de validación, asegurando que el sistema cumpla con los estándares necesarios de fiabilidad y precisión antes del despliegue a gran escala.
A través de este proceso, la plataforma ya ha permitido el desarrollo de mecanismos de análisis de diagnóstico que se encuentran actualmente en uso, probados en entornos reales que respaldan su eficacia (Nuñez, 2024). Estos sistemas de diagnóstico permiten a los operadores visualizar y rastrear fácilmente el comportamiento de los datos, destacando cuándo los valores comienzan a desviarse de su rango nominal, lo que proporciona indicadores tempranos de posibles problemas. Se muestra un ejemplo en la Figura 5.
Resultados y discusión
El desarrollo del algoritmo de detección de anomalías ha generado varios conocimientos valiosos y ha puesto de relieve algunos desafíos clave.
• El concepto de “Golden Batch” ha demostrado ser una base útil para definir un punto de referencia del comportamiento nominal. Al recopilar datos de múltiples ejecuciones de producción y establecer una línea base, la plataforma cuenta con un marco teórico sólido para evaluar las desviaciones. Esto permite una distinción más clara entre operaciones normales y anomalías potenciales.
• Sin embargo, la alta variabilidad entre máquinas y procesos sigue siendo el principal desafío para generalizar el algoritmo. Cada liofilizador y sus recetas asociadas presentan fluctuaciones en los parámetros operativos, lo que complica el establecimiento de un algoritmo de aplicación universal. Estas variaciones en las condiciones ambientales, los ajustes de la máquina y los materiales significan que el "Golden Batch" no puede servir fácilmente como una referencia estática en todas las máquinas sin una mayor optimización.
• A pesar de ello, el análisis descriptivo ha demostrado ser eficaz para crear sistemas de diagnóstico que sirven como capa fundamental para el desarrollo del algoritmo. Estos análisis permiten a los operadores monitorear las desviaciones del comportamiento normal, incluso cuando el sistema completo de detección de anomalías aún no está completamente optimizado. Las herramientas de diagnóstico actuales brindan información útil que ya se utiliza para mejorar el rendimiento de las máquinas y la programación del mantenimiento.
• Las tecnologías actuales han demostrado su utilidad para respaldar las plataformas de mantenimiento predictivo, pero requieren un mayor desarrollo para manejar las complejidades de los entornos industriales del mundo real. Si bien el algoritmo de detección de anomalías es prometedor, será necesario realizar pruebas exhaustivas, realizar ajustes y adaptarlo para garantizar que el sistema pueda manejar la variabilidad inherente de los procesos de liofilización en diferentes máquinas y ciclos operativos.
Conclusión
El desarrollo continuo del algoritmo de detección de anomalías dentro de la plataforma de mantenimiento predictivo para liofilizadores ha demostrado el potencial de las técnicas analíticas avanzadas para mejorar la eficiencia operativa. La integración del concepto de "Golden Batch" proporciona una base sólida para identificar desviaciones en el comportamiento del proceso que podría aplicarse en todos los equipos farmacéuticos, aunque persisten los desafíos relacionados con la variabilidad entre máquinas y las condiciones del proceso. La capacidad de detectar anomalías de forma temprana mediante la combinación de metodologías automatizadas y manuales ofrece una promesa significativa para reducir el tiempo de inactividad y los costos de mantenimiento.
A pesar del progreso, el rendimiento del algoritmo continúa perfeccionándose mediante pruebas y validaciones exhaustivas. Los esfuerzos futuros se centrarán en mejorar la precisión de la detección de anomalías, definir valores umbral precisos y adaptar el sistema a diversos contextos operativos. Los resultados obtenidos hasta ahora ponen en valor la eficacia del uso de las tecnologías de big data y la analítica avanzada en el mantenimiento predictivo, sentando las bases para futuros avances en este ámbito.
Bibiografía
Nuñez, J. (2024). New trends: optimizing equipment performance and availability by implementing a smart maintenance platform. CPHI.
Descarga sugerida:
Artículo escrito por:
Aitor Rodríguez
Especialista en transformación digital
,Telstar